Multitask Deep Neural Networks for Natural Language Understading 是微軟發在 ACL 2019 的論文:論文連結。
論文概要
這篇論文很簡單,兩張圖清楚地說明了這篇論文做了什麼事情:
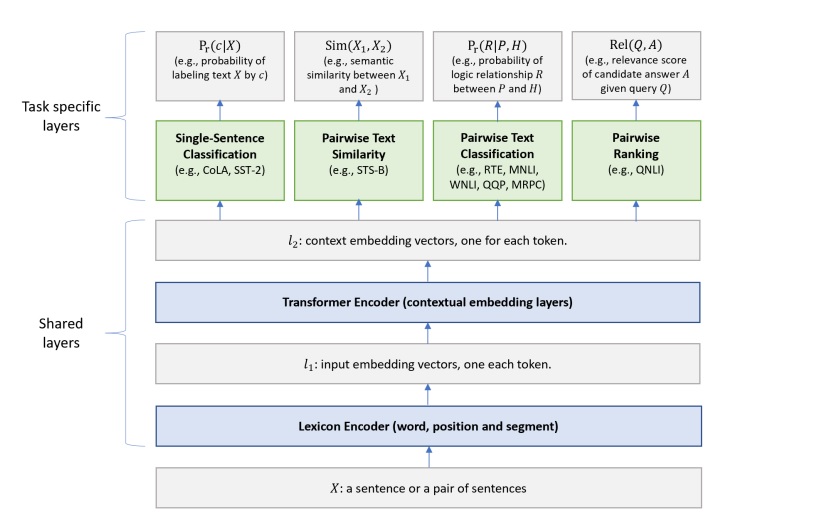
網路架構分成 shared-layers 跟 task specific layers 兩個部份:shared layers 用一個好的 NLP backbone model (這篇用 BERT) 學出輸入文字的 embedding,task specific layers 再根據不同的任務學每個任務各自的 loss。

訓練的時候,再根據這個演算法做訓練:有 T 個任務,所以打包好 T 個 dataset,把他們混在一起。訓練的時候,每次訓練一個 batch,因為每個 batch 都屬於某個特定的任務,所以就根據該任務的 loss 對模型做訓練。
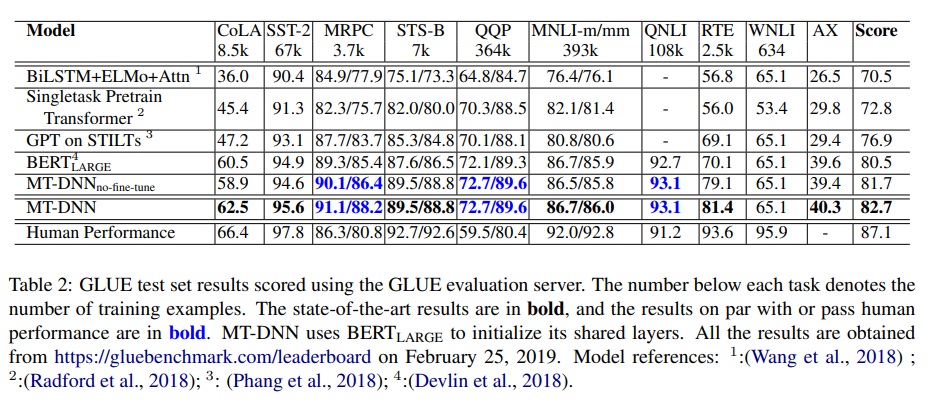
實驗結果也可以看到,shared layers 用 BERT 可以打敗 BERT。
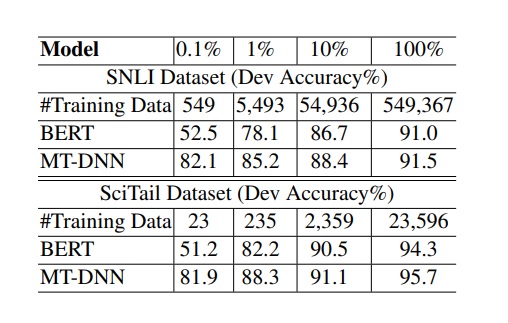
作者們也做了另外一個實驗,在新增 SNLI 任務的時候,MT-DNN 只要 549 筆訓練資料就可以做到 82.1% 的準確率,BERT 在相同資料述的情況下只能做到 52.5% 的準確率。可以知道 MT-DNN 對新任務 cold start 是有幫助的。
個人經驗
我在工作上有嘗試使用 MT-DNN,除了論文提到的好處以外,還有一個額外的好處:因為 shared layers 是同一個,task specific layers 都相對很淺,所以如果應用需要同時預測兩個以上的任務,可以幾乎只用一半的時間產出兩種預測 (相對於跑兩次不同的模型)。
實際上在訓練的時候,雖然論文沒有特別提,但是訓練結果還是會因為不同 loss 不同的數值大小影響到訓練的平衡。實際在訓練的時候不同數值範圍的 loss 還是要給不同的權重。本來以為論文沒特別提是因為沒有這個問題。
深度學習是一個需要資料的領域,有好的資料才會有好的結果,尤其是有正確答案的資料。這篇論文讓我想到 Facebook 用 instagram 的影像加上 hashtag 做出比 imagenet 更好的模型。這篇也是從 public dataset 想辦法找出更多的資料,來得到更好的成效。