自監督學習 (self-supervised learning) 是最近開始很熱門的題目,個人認為也是機器學習中充滿潛力的領域。本文會介紹什麼是自監督學習,以及相關的應用。
什麼是自監督學習
我們手上有一堆沒有 label 的資料,想辦法用資料本身做出 label,而後用這些 label 訓練一個監督式模型。一個簡單的例子就是 word2vec,從沒有任何 label 的文本開始,假設一個字的意思可以用它附近的字來解釋,於是乎我們可以把出現在兩個附近的字當成 positive pair,隨機抽取的兩個字當成 negative pair,有兩個 class 的資料之後,由此來訓練監督式的模型。
通常學完以後,會當做初始的權重,再根據要做的任務做 fine tune 或是第二次的訓練。像是做文件分類可能會拿 word2vec 訓練好的權重當做特徵,再用其他模型 (可能是 random forest 或 logistic regression) 訓練一個文件的分類模型。或是類神經網路先用沒有標註的資料做自監督學習,學完以後再用這個當做起始點,訓練我們真正要解的任務。
自然語言處理的應用
除了 word2vec 以外,BERT 也是另一個知名的應用。BERT 在預訓練的時候,訓練了兩個自監督的任務:Masked Language Modeling 跟 Next Sentence Prediction。
Masked Language Modeling
Masked Language Modeling 做的事情就是,把一句句子中的幾個字隨機遮住 (變成特殊的[MASK]token),然後預測這些被遮住的字是哪些字,就是國高中英文考試常見的克漏字。在 BERT 中,每個 token 有 15% 的機率被代換,被代換的 token 有 80% 的機率變成[MASK],有 10% 的機率變成隨機 token,有 10% 的機率不變。讓模型去預測原本是什麼 token,用 cross entropy 訓練。
Next Sentence Prediction
Next Sentence Prediction 很直觀,給兩個句子,預測第二句是不是第一句的下一句。是跟不是各抽取 50%。
Sentence Order Prediction
ALBERT 是 BERT 的續作,論文全名是:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations。論文內容是用比 BERT 更少的參數量得到比 BERT 更好的結果。裡面用了另一個自監督的任務:Sentence Order Prediction。
Sentence Order Prediction 做的事情跟字面意義一樣,找連續的兩個句子,當 positive pair,把他們順序顛倒,當做 negative pair。讓模型去預測句子有沒有顛倒。
影像處理的應用
自監督學習在影像處理上也有很多應用:
旋轉
Unsupervised Representation Learning by Predicting Image Rotations 對圖片做隨機的 0 度、90 度、180 度、270 度旋轉,然後讓模型預測旋轉多少度。
相對位置
Unsupervised Visual Representation Learning by Context Prediction 讓模型學習圖片的相對位置。
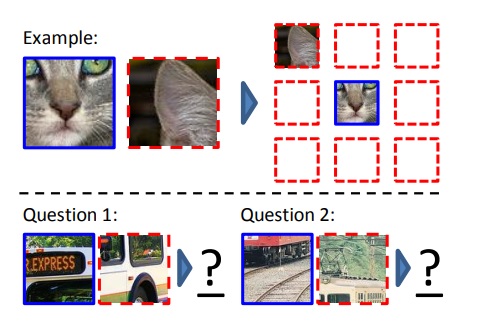
如上圖,從圖片中隨機取一個 patch,擺到 3x3 的 grid 中間。再從周遭八個隨機取一個 patch,讓模型學這兩個 patch 的相對位置。為了避免任務太簡單可以直接從邊界相鄰猜到答案,而不是真正學會 patch 間的相對關係,用以下方式增加任務難度:
- Patch 間不直接相鄰,隔了半個 patch 的間隔。
- Patch 位置加入小的上下左右變化,不是方正的九宮格。
- 將圖片減掉其在 綠 - 洋紅 (紅 + 藍) 座標上的投影 (這邊不是很確定,有誤請指正),或是隨機選取兩個 color channel 用 Gaussian noise 取代。
- Downsample 到總共 100 pixel,再 upsample 回到原本大小。
著色
Colorful Image Colorization 學習怎麼幫圖片上色。輸入灰階圖片,輸出在 CIE Lab space 上的圖片 (有對顏色做 quantization)。
結語
深度學習需要大量資料,而這個方法可以讓我們「便宜地」得到大量有答案的資料,所以我認為是一個充滿潛力的領域。很多實務上的問題沒辦法直接對應到論文中的問題,不過自監督的概念還是可以參考。