Self-supervised learning is a very popular topic that has gained attention recently, and I personally believe that it is a very promising field in machine learning. This article will introduce what self-supervised learning is and its related applications.
What is Self-supervised Learning
We have a set of unlabeled data and want to find a way to label it using the data itself, and then use these labels to train a supervised model. A simple example of this is word2vec, which starts with unlabeled text and assumes that the meaning of a word can be explained by the words around it. We can then treat pairs of words that appear near each other as positive examples, and pairs of words randomly selected as negative examples. With this data, we can train a supervised model with two classes.
After completing training, the learned weights are typically used as the initial weights, and then fine-tuned or retrained according to the specific task at hand. For example, in document classification, pre-trained word2vec weights may be used as features, and another model (such as a random forest or logistic regression) is trained on the features to classify documents. Alternatively, a neural network may first be trained on unlabeled data using self-supervised learning, and the learned weights are then used as a starting point to train the actual task at hand.
The Applications in Natural Languague Processing
Besides word2vec, BERT is another popular application. BERT is pre-trained by the following tasks: masked language modeling and next sentence prediction.
Masked Language Modeling
Masked language modeling involves randomly masking (replacing with a special [MASK] token) several words in a sentence and then predicting what those masked words were. In BERT, each token has a 15% chance of being replaced, with an 80% chance of being replaced with [MASK], a 10% chance of being replaced with a random token, and a 10% chance of not being replaced. The model is trained to predict the original token using cross-entropy loss.
Next Sentence Prediction
Next sentence prediction is intuitive. Given two sentences, predict whether the second sentence is the next sentence of the first sentence. There is a 50% chance of it being true and a 50% chance of it being false.
Sentence Order Prediction
ALBERT is a successor to BERT, and its full name is “ALBERT: A Lite BERT for Self-supervised Learning of Language Representations.” The paper discusses using fewer parameters than BERT to achieve better results. Another self-supervised task called “Sentence Order Prediction” is used, where the goal is to take two consecutive sentences and use one as a positive pair and the other as a negative pair by reversing their order. The model is trained to predict whether the sentences are in the correct order or not.
The Applications in Computer Vision
Self-supervised learning also has many applications in computer vision:
Rotation
Unsupervised Representation Learning by Predicting Image Rotations rotates images randomly by 0, 90, 180, or 270 degrees, and then have the model predict the degree of rotation.
Relative Position
Unsupervised Visual Representation Learning by Context Prediction has the model learn the relative position of the images.
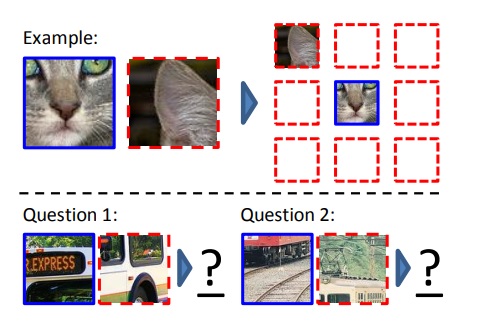
In the image shown above, a random patch is taken and placed in the center of a 3x3 grid. Another patch is randomly selected from the eight patches surrounding it to train the model on their relative positions. To avoid making the task too easy, where the answer can be guessed by simply adjacent pixels, without actually learning the relative positions between patches, the following measures are taken to increase the difficulty of the task:
- The patches are not directly adjacent, but are separated by a half-patch interval.
- Small random variations are introduced to the patch positions.
- The image is subtracted from its projection onto the green-cyan (green + blue) coordinate axis (not entirely sure about this, please correct if wrong), or two color channels are randomly selected and replaced with Gaussian noise.
- The image is downsampled to a total of 100 pixels and then upsampled back to its original size.
Coloring
Colorful Image Colorization has the model learn how to color images. Input an grayscale image, and output it to CIE Lab space (with color quantization).
Conclusion
Deep learning requires a large amount of data, and self-supervised learning allows us to obtain a large amount of label data “cheaply”. I believe it is a promising direction. Many practical problems cannot be directly mapped to problems in papers, but the concept of self-supervision can still be used.