Multitask Deep Neural Networks for Natural Language Understading was published on ACL 2019 by Microsoft.
Summary
This paper is very simple, and the figure below clearly shows what this paper has done.
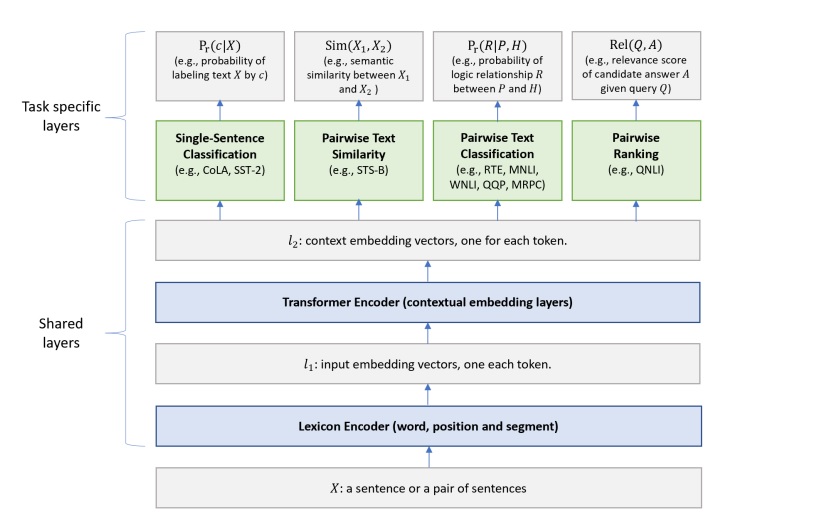
The network architecture is divided into two parts: shared layers and task-specific layers. The shared layers use a good NLP backbone model (BERT in this article) to learn the embedding of input text, and the task-specific layers then learn the loss for each task based on different tasks.

During training, follow this algorithm: if there are T tasks, prepare T datasets and mix them together. When training, train one batch at a time, and because each batch belongs to a specific task, train the model based on the loss for that task.
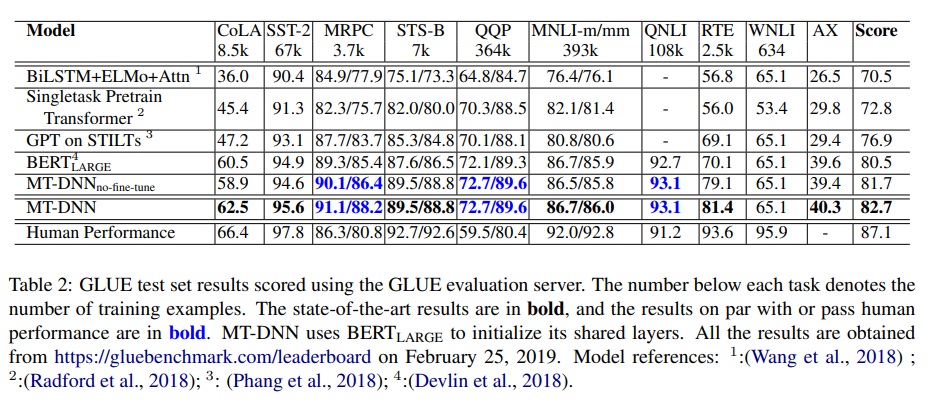
The experimental results also show that using BERT as shared layers can outperform BERT.
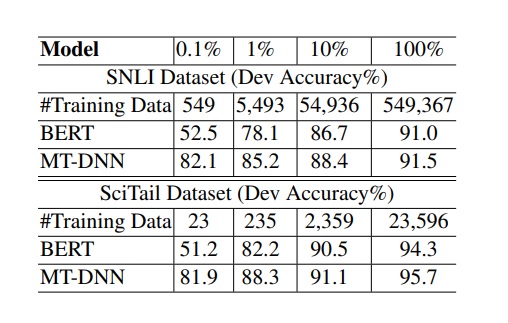
The authors also conducted another experiment where they added the SNLI task. In this case, MT-DNN achieved an accuracy of 82.1% with only 549 training examples, while BERT could only achieve an accuracy of 52.5% on the same data. This shows that MT-DNN is helpful for cold starting new tasks.
My Experience
I have tried using MT-DNN at work and found an additional benefit beyond what was mentioned in the paper. Because the shared layers are the same, the task-specific layers are relatively shallow. This means that if an application needs to predict two or more tasks simultaneously, it can produce two predictions in almost half the time compared to running two separate models.
In practice, although the paper did not specifically mention it, the training results will still be affected by the different numerical ranges of the losses, which will affect the balance of the training. In actual training, different weightings should still be given to losses with different numerical ranges.
Deep learning is a field that requires data, and good data leads to good results, especially data with correct answers. This paper reminds me of Facebook using images from Instagram along with hashtags to create a better model than ImageNet. This paper also focuses on finding more data from public datasets to achieve better results.